Back
Complexity and Transformers
Summary
Can a simple transformer solve problems that constant-depth circuits cannot? Yes—we discuss a result due to Merrill et al. showing that a restricted model for transformers can solve the MAJORITY problem, which sits outside of the circuit class . This implies that softmax attention has power beyond that of constant-depth Boolean circuits, and provides insight into how tools from complexity can be used to analyze the expressivity of different model architectures.
A Gentle Intro to Complexity Theory
The primary goal of complexity theory is to understand the difficulty of computational problems. In this section, we aim to refine that statement by answering the following questions: what are some reasonable definitions of computational difficulty? And how can we effectively group problems together so that they may be studied as a collective? This section is intended to be a primer in complexity theory for those coming from a machine learning background and can safely be skipped.
We are obligated to begin with a particularly famous example: the vs. problem. The Clay Mathematics Institute is currently offering a $1 million prize to the person who is able to crack it (definitely one of the harder ways to make a million dollars). The problem is, at a philosophical level, about how the difficulty of verifying a correct solution compares to the difficulty of computing a correct solution. The prevailing view is that the latter is strictly harder, and much of modern cryptography rests on related hardness assumptions.
 Figure 1: P = NP? (barely legible) on the wall of the Princeton CS building[8].
Figure 1: P = NP? (barely legible) on the wall of the Princeton CS building[8].
Let's illustrate the problem with an example. Suppose that you are given a set of integers which are purported to be the prime factorization of . You are skeptical and would like to check this claim for yourself. Fortunately, you can do this quite easily: first verify that each is prime (there is a deterministic polynomial-time algorithm for this due to Agrawal et al.[1]) and then multiply the together to make sure that their product is . This verification algorithm runs in time polynomial in the length of the input .
But what if you wanted to find the prime factorization of yourself (i.e., compute a solution)? Could you do so for an arbitrary , without simply using naive trial division up to (which takes time exponential in the input length )? If indeed there were an efficient algorithm for this problem, it would break RSA-style cryptosystems, but notably its existence would not resolve the vs. problem1.
Now for a more precise definition: is the class of decision problems that admit a polynomial-time (polytime) solution. More concretely, a language is in if there exists a deterministic algorithm and a polynomial such that on each input , halts within steps and if and only if . Here "language" refers to the set of yes-instances for a particular decision problem. As an example, the following language defines a decision version of integer factoring
.
A problem is in the class if and only if it admits a verifier that, given an input and a proposed solution, checks correctness in polytime. Earlier, we exhibited such a verifier for a decision version of integer
factoring. In that case, the proposed solution consisted of the input
together with integers claimed to factor
; this extra piece
is called a certificate (or witness) and is required to have length
polynomial in . The vs. problem asks whether
every problem with efficiently verifiable certificates can also be solved
efficiently—i.e., whether and are actually the same set.
We have seen two different ways of grouping infinite sets of problems, and in both cases, we used time complexity as a measure of difficulty. Other measures of difficulty include space complexity and bits of communication, and there is a whole zoology of problem classes that result from these[6]. Another interesting example is the class which is the set of problems that can be solved by a polytime randomized verifier interacting with a (potentially adversarial) computationally unbounded machine. It turns out that exactly captures the problems that can be solved with polynomial space[2].
Short Circuit
The vs. problem concerns the limits of efficient computation on Turing machines which is the model that best captures the capabilities of classical computers (the Church-Turing thesis posits that Turing machines exactly capture the power of computers). We will now switch from Turing machines to circuits, which will generate a classification scheme that is more useful for studying transformers.
A (Boolean) circuit is a finite DAG with Boolean gates (i.e., NOT, AND, and OR). Let's assume that we would like to use circuits to solve decision problems; in particular, we will consider circuits that have just one output gate. The architecture of a circuit, including the number of input gates it has, is not allowed to change according to its input so a separate circuit is required for each input length. Thus, to solve a decision problem on all input lengths, we will need an infinite family of circuits, , where computes on inputs of length . In this sense, circuits are non-uniform: the circuits may have different structures and it may even be the case that there is no single finite algorithm that can generate them all. This is in contrast to Turing machines, which have a single finite description used for all inputs.
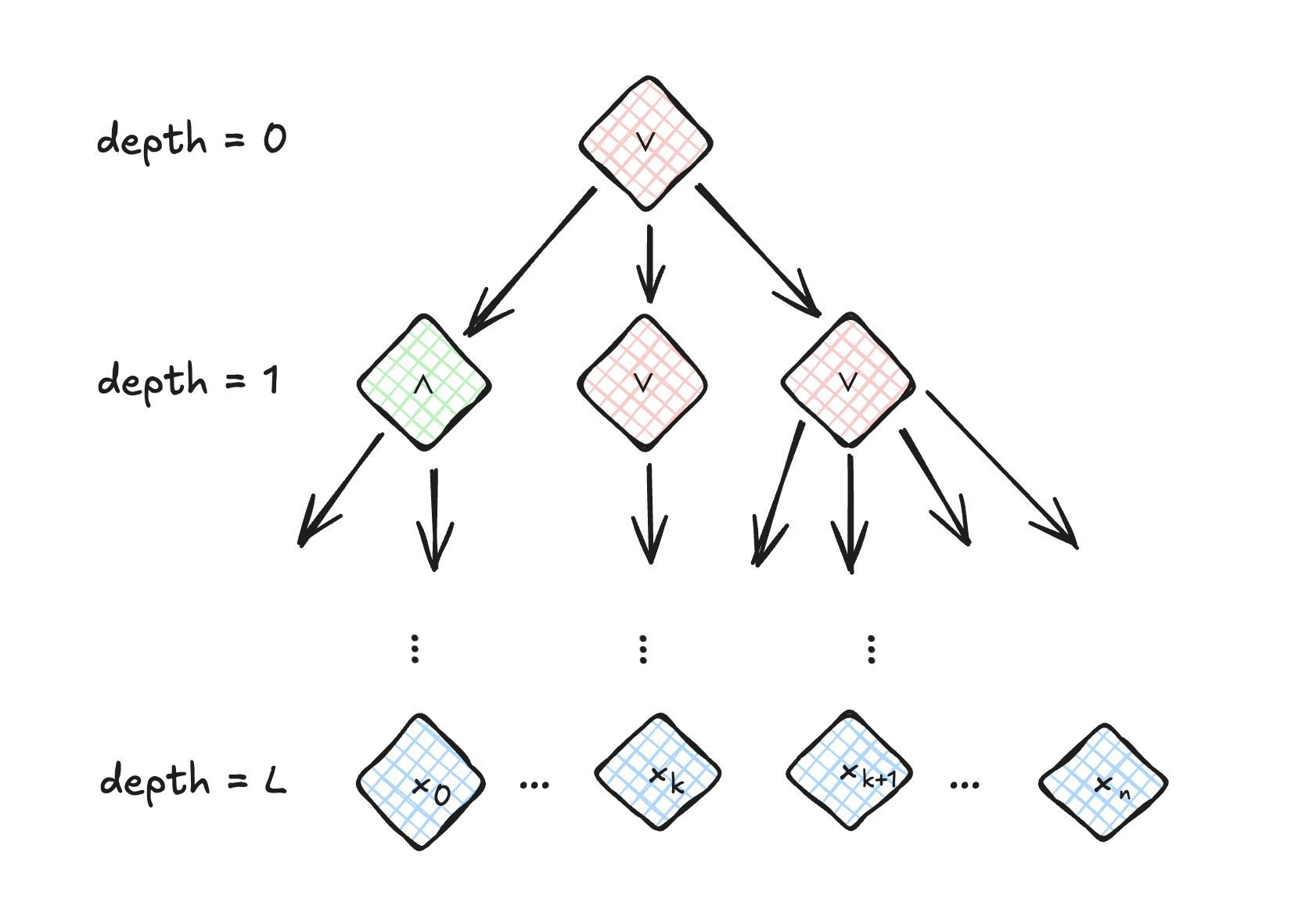 Figure 2: A simple circuit, with depth , a single output gate, and input gates.
Figure 2: A simple circuit, with depth , a single output gate, and input gates.
One way to measure the difficulty of a problem is by the size of the smallest circuit family that can solve it. More concretely, if there exists a family of circuits such that for all , and for each with , we have and has at most gates. The set of problems that can be solved by circuits with polynomially many gates is called and one can show that . So in particular, if then . That is, if requires superpolynomial-sized circuits then .
The depth of a circuit is the length of the longest path from the output node to any input node. We can think of depth as measuring the extent to which a computation can be parallelized. For example, the circuit in Figure 2 has levels (where each level is the set of nodes with the same distance from the output layer). The nodes in level depend on the computation done in levels which determines the inputs to the layer. However within a layer, there is no interdependence between nodes. Thus, problems that can be solved by circuits of low depth are more parallelizable. We will use these complexity metrics—size and depth—to define the class , which will come up in our discussion of transformers.
Definition. is the class of problems that are computable by circuits with polynomial size and constant depth. Additionally, nodes are allowed to have unbounded fan-in.
Optimus Prime
Transformers are not circuits, nor are they Turing machines. The method by which transformers compute answers to problems is fundamentally different from either of these other models of computation. Hao et al. formally define a (restricted) model of computation for transformers called where is the data type on which the transformers operate[7]. We will define the high-level features of this class when we discuss a fundamental result in transformer complexity which helped to spur current research in the area. For the remainder of the article, we will use to denote the set of floating-point numbers with bits of precision.
Definition (Saturated Attention). For attention scores , let be the set of indices attaining the maximum. Note that if has a unique largest entry, then will be a singleton. We define the saturated attention of as
Intuitively, defines a discrete uniform distribution over maxima. Observe that saturated attention is the zero-temperature limit of traditional softmax attention,
Vanilla softmax attention heads often learn diffuse distributions over tokens, making this model of attention fairly unrealistic. However, we can use this simplified model to prove a theorem on the expressivity of transformers. First, we need to define what it means for a so-called saturated transformer to recognize a language: a saturated transformer recognizes a language if there exists an affine linear transformation such that if and only if . In particular, separates positive examples from negative ones using the -axis. We will refer to as an attention readout.
Theorem (Merrill et al. [3]). Saturated transformers with bits of floating-point precision can compute problems outside of .
Proof outline: Let
Since it suffices to show that saturated transformers can recognize . We can do this with a 1-layer, 1-head transformer. These are its components:
- Positional embedding: Let be a one-hot encoding 2. In particular, for a sequence , the -th token is encoded as:
Let denote the -th token after applying positional encoding, and let be the matrix of these encodings .
- Attention scores: the score function is constant at 1. That is, for each , , so attention is uniform over all tokens. Note that we are constructing a transformer with a single head and a single layer, so there is only one score function to specify.
- Post attention: we describe a single function that computes the post attention layer, per-position update. In a vanilla transformer, would apply the FFN, residual connection and layer norm(s). We use .
- Attention readout: Let and where denotes a row vector of all 1s.
Let be the attention score vector defined as . Observe that for each and
Let . Finally, since we have
This quantity is greater than zero exactly when there are more 1s than 0s in . Hence, this transformer recognizes .
Merrill et al. go on to show that floating-point saturated transformers can be simulated by threshold circuits, giving an upper bound on their expressivity. Briefly, threshold circuits are allowed to use gates that activate when the number of input 1s is above or below a certain fixed threshold. The class of problems that can be solved by threshold circuits of constant depth is called , so formally, the containment result is .
Takeaways
We showed how tools from complexity theory can be used to analyze a restricted transformer model called floating-point saturated transformers, and we contextualized the expressivity of this model using Boolean circuit classes. This kind of classification has proven to be useful both in motivating new architectures and understanding the fundamental limitations of current ones.
We allowed saturated transformers the freedom of using bits of floating-point precision, which we used when defining the positional embedding function . Intuitively, this assumption bounded the memory of our transformer model to be (each of the input tokens uses bits). This amount of memory sufficed for representing token indices and counts up to , ensuring the saturated-attention construction was well-defined. In practical settings, there will be a fixed maximum context window length ; choosing a fixed float type with mantissa at least bits will then recover the same behavior.
Merrill & Sabharwal extended the containment result to softmax-attention transformers, showing that they can also be simulated by circuits[4]. Behrouz et al. find that Titans can compute problems outside of , making them theoretically more expressive than both softmax-attention transformers and other test-time learners like DeltaNet[5]. As a future direction, we are interested in studying the gap between a transformer’s theoretical expressivity and what it can actually learn in realistic training settings. In other words, given a function that a transformer is capable of representing, can practical training setups (objective, optimizer, data, precision/compute) reliably recover it?
References
- Agrawal, Manindra and Kayal, Neeraj and Saxena, Nitin (2004).
- Shamir, Adi (1992).
- Merrill, William and Sabharwal, Ashish and Smith, Noah A. (2022).
- Merrill, William and Sabharwal, Ashish (2025).
- Behrouz, Ali and Zhong, Peilin and Mirrokni, Vahab (2024).
- Aaronson, Scott and contributors (accessed 2025).
- Hao, Yiding and Angluin, Dana and Frank, Robert (2022).
- Wayne, Kevin (2018).
Footnotes
-
Integer factoring is believed to be an -intermediate problem. These problems do not fully capture the hardness of (i.e., they are not complete for ) and so it is possible that integer factoring has an efficient algorithm, while other problems in do not. ↩
-
We don't actually need positional information to solve but we still define this way so that it is size-preserving, which is a requirement of the saturated transformers model. ↩